Fusing Text and Images
CLIP is one of the first large-scale models to fuse text and image representations effectively, demonstrating strong zero-shot generalization across vision tasks. Multimodal learning—combining different types of data—may be a crucial step toward more general forms of artificial intelligence, possibly even AGI.
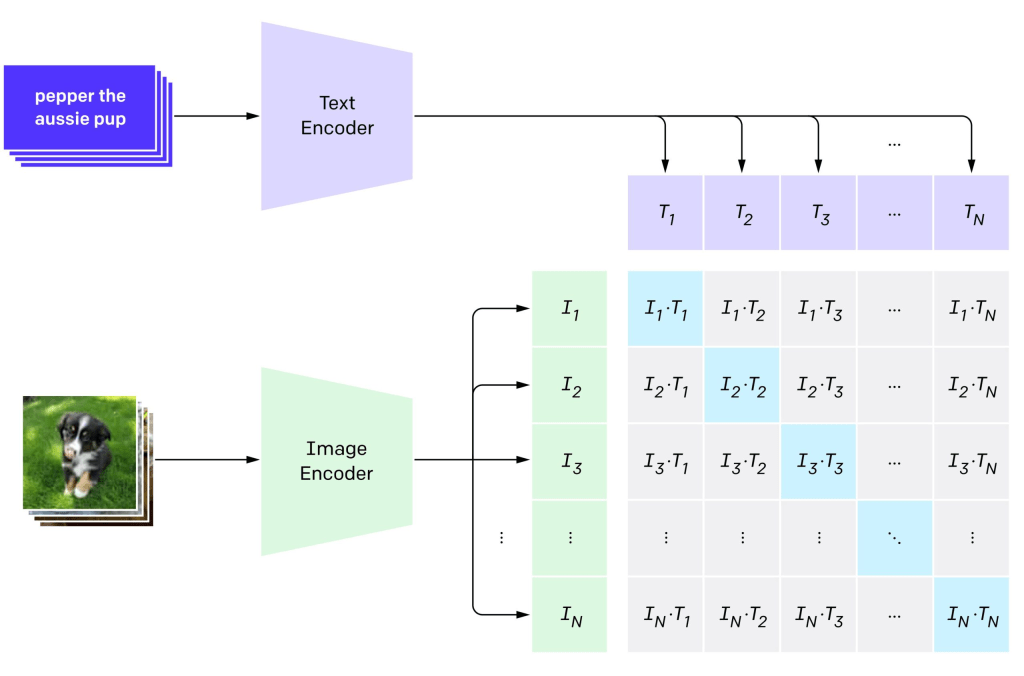

Image taken from:https://www.appypiedesign.ai/api/image-to-text/llava-1.5-api
Vision-Language Model: LLaVA
Read about the architecture of LLaVA and a case study of fine tuning LLaVA for a downstream task.
Subscribe for to hear more about my work
Engineering notes, implementations, new libraries and more….
